19157628936
lx@jinglianwen.com
时间:2022-10-24 12:09:59

作者:欧陆注册科技

浏览: 次
自动驾驶数据标注是通过使用边界框和定义其他属性来标记图像或视频中的车、人、物的过程,教会模型识别行人啊、车啊、交通标识等等交通要素,以帮助 ML 模型理解和识别车辆中传感器检测到的对象。

实现自动驾驶的基础是人工智能,实现人工智能的基础又是什么?答案是:自动驾驶数据标注。
目前,自动驾驶急需解决四个重大问题:看得见(定位、避障)、听得着(决策、控制、执行)、讲得出(路径规划、行车方式)、有大脑(边缘计算)。
1. 摩托车;2. 自行车;3. 骑摩托车/自行车的人;4. 前后轮线;5. 三轮车;6. 行人;7. 交通灯;8. 交通指 示牌;9. 无所谓物体;10. 车罩;11. 可忽略杆;12. 地平线;13.其他动物。

自动驾驶数据标注中有哪些类型?路上静态和动态的事物错综复杂,应该通过什么方式对这些物体进行标注呢?不同的物体及区域的标注类型又是怎样的?
1、拉框标注
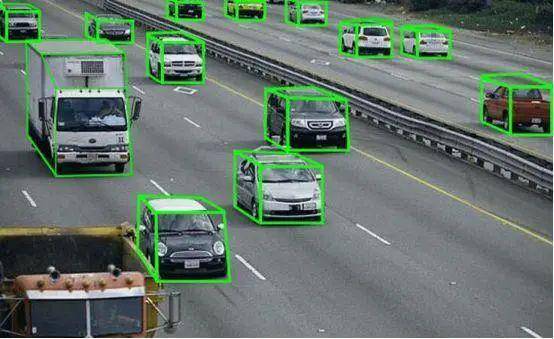
拉框标注主要指用2D框、3D框、多边框等标注出图像中指定目标对象。应用于对车辆与行人的基础识别,即标注出骑行的人、步行的人、汽车。包括将平面图片中的车辆进行3D标注,主要应用于训练自动驾驶对会车或超车车辆的体积判断,为汽车建立对行人、车辆的完整认知。
2、语义分割
语义分割是计算机视觉中非常重要的标注任务,对图片中的不同区域进行分割标注:这些可能是“行人、车辆、建筑物、天空、植被等等。例如,语义分割可以帮助自动驾驶车辆识别一个图片中的可行驶区域。

自动驾驶领域常见的标注类型中图像语义分割是应用较为广泛的一种标注类型。从概念上来看,图像语义分割属于人工智能计算机视觉领域的一个重要分支,它结合了图像分类、目标检测和图像分割等技术,主要针对图像进行像素级的分类。
3、3D点云标注
3D点云是一种非常适合于3D场景理解的数据,因为点云非常接近原始传感器的数据集,激光雷达扫描得到的就是点云,而深度图像就是点云的一个局部部分,原始的数据就可以实现端对端的深度学习。
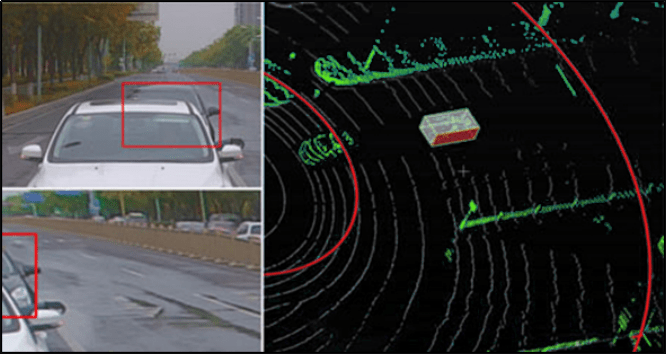
与2D图像相比,3D点云可以提供更多维度的信息,例如:几何、形状、尺寸信息。3D点云标注从激光雷达采集的点云图中找出目标对象,并以立方体框的形式标注出来,不易受光照强度变化和其它物体遮挡等影响。目标物体包括车辆、行人、广告标志和树木等,供计算机视觉、自动驾驶等人工智能模型训练使用。
自动驾驶汽车要从 A 点到达 B 点,它需要完美地掌握周围环境。您想要在汽车中实现的驾驶功能的典型用例可能需要两个相同的传感器组。一个是您的被测传感器组,另一个传感器组将作为参考。
案例分析:
现在让我们假设一辆汽车在不同的驾驶条件下以每小时 45 公里的平均速度行驶 3,00,000 公里。使用这些数字,我们将知道车辆需要 6700 小时才能走完这段距离。汽车可能还有多个摄像头和 LIDAR(光探测和测距)系统,如果我们假设它们在这 6700 小时内以每秒 10 帧的速度记录,那么将生成 240,000,000 帧数据。假设每帧平均可能有 15 个对象,其中包括其他汽车、交通灯、行人和其他对象,那么我们最终将拥有超过 35 亿个对象。所有这些对象都必须被标注。
仅仅标注是不够的;它也必须准确。在此之前,我们无法在车辆上的传感器组之间进行有意义的比较。那么,如果我们必须手动标注每个对象呢?
现在仅仅放置边界框和广义标注作为汽车、行人、停车标志等可能还不够。您将需要最能描述对象的适当属性。除此之外,您还需要了解刹车灯、停车标志、移动物体、静止物体、应急车辆、灯的分类、应急车辆有哪些警示灯等。这需要详尽列出物体和它们对应的属性,其中每个属性必须一次处理一个。这意味着我们正在谈论大量数据。
完成此操作后,您还需要确保您拥有正确的标注;另一个人需要检查标注数据是否正确。这确保了最小范围的错误。如果这项活动是手动完成的,每个对象平均需要 60 秒,那么我们将需要为我们之前讨论的 36 亿个对象花费 6000 万小时或 6849 个日历年。因此,手动标注似乎不可信。
AI智能标注工具提升效率
从上面提到的例子中,我们了解到手动标注数据的可能性很小。各种开源工具可以帮助我们完成这项活动。尽管有不同的角度、低分辨率或低光照条件,都可以自动检测物体。由于深度学习模型,这成为可能。谈到自动化,第一步是创建标注任务。首先命名任务,指定标签和与之关联的属性。完成此操作后,您现在可以添加需要标注的可用数据存储库。
除此之外,许多附加属性可以添加到任务中。可以使用多边形、框和折线来完成标注。不同的模式,即插值、属性标注模式、分割等。
自动化减少了标注数据所需的平均时间。结合自动化至少可以为您节省 65% 的精力和精神疲劳。
根据您的阅读内容,您可能对以下内容感兴趣:
