19157628936
lx@jinglianwen.com
时间:2022-10-24 12:27:17

作者:欧陆注册科技

浏览: 次
上一期我们简单介绍了人工智能数据标注(二)文本标注,本期我们来介绍一下图像识别的图像标注。
首先,我们先援引一下知乎上的一篇帖子对机器学习的简单解释:
识别手写的数字“8”
图像识别是建立在我们有一定量的数据的情况下实现的,所以首先我们得有大量的手写体的“8”,刚好MINIST提供了一个手写数字的图片库,且每一张都是18*18的图片:

MNIST数据库中的数字“8”
神经网络本不能识别图像,但神经网络会把数字当成输入,但对于电脑来说,图片恰好就是一连串代表着每个像素颜色的数字:

手写体数字“8”
我们把一副18×18像素的图片当成一串324个数字的数列,就可以把它输入到我们的神经网络里面了:

输入到神经网络中的手写体“8”举例
为了更好地操控我们的输入数据,我们把神经网络扩大到拥有324个输入节点:
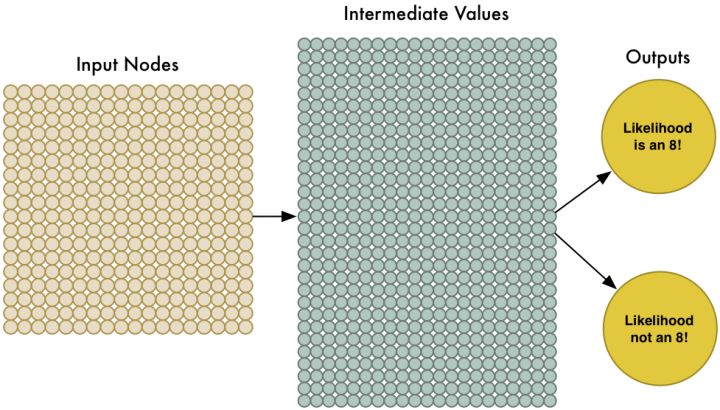
第一个输出会预测图片是“8”的概率 而第二个则输出不是“8”的概率。概括地说,我们就可以依靠多种不同的输出,利用神经网络把要识别的物品进行分组。
现在唯一要做的就是训练我们的神经网络了。先对大量的各种“8”和非“8”的图片进行标注,相当于对于我们判定为“8”的图片,我们明确告诉它我们输入的图片是“8”的概率是100%,不是“8”的概率是0,对应的非“8”的图片,我们明确告诉它我们输入图片的是“8”的概率是是0,不是“8”的概率是100%。
下面是一些训练数据:

嗯…就是这些训练数据…
我们现在能在我们笔记本电脑上面用几分钟的时间来训练这种神经网络。完成之后,我们就可以得到一个有着很高的“8”图片识别率的神经网络。
(内容经过我的一些编辑,个人感觉能够更好的理解这个简单过程,原贴地址:http://www.zhihu.com/question/27790364,对机器学习讲得更深度,有需自取。)
好了,现在回到我们的图像数据标注,图片的标注现在主流的应用范围有自动驾驶,人像识别,图片内对象识别,还有我们做的比较非主流的应用范围医疗图像识别。
自动驾驶和图片内对象识别的标注原理差不多,标注方式主要有两种,一种是拉框标注,一种是精细的切割标注。
首先我们来看拉框标注:
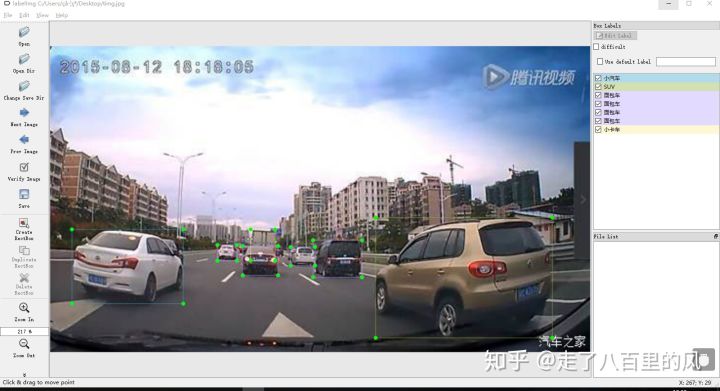
这就是车辆的拉框标注了
这是一个车辆拉框标注的例子,图片中标注了小汽车、SUV、面包车和小型货车,标注的时候我们将框的边紧贴车辆边缘,同时注明每一个框的属性,对于算法来讲,每一个框都是一个小图,每一个小图对应一种车。
标注的时候需要特别注意框与车辆的边缘相切,如果不相切,比如把不属于车辆的部分框选了进来,那么机器在学习的时候就有可能将多框选进来的部分识别为车辆,从而造成机器识别不准确甚至是错误;另外在选框的属性的时候也是一样,如果本来是小汽车,但是标记成了卡车,相当于我们是告诉机器这个小汽车是卡车的概率是100%,机器学习的时候用一句形象一点的话来讲,这种时候机器就懵逼了,它不知道正确与否了。
而我们之所以需要大量的数据,是机器算法在大量数据的学习中,会自行总结这些对象的高维特征,在识别新图像时能够通过自己总结的高维特征对新的图像进行判断,对每一种可能的结果给出一个概率。
人像的识别相对于物体的对象识别来讲,所用的原理就不太一样了,现在应用得比较多的方式是在人脸上定位多个标志点,也就是我们现在做的人脸关键点的标注,每一个点都对应一个特征位置,从最基础的五点标注到多的几百点的标注:

这是来自CSND上一篇人脸关键点识别的27点标注图例
以上图为例我们可以看到,1-3号3个点位分别对应了眉毛的两端和中心点位,7-11号点分别对应了眼睛的左右角上下眼睑中心位和眼球中心位,余下的点位同理我们再图片中可以看到就不赘述了。
明确的是,每一个点代表一个关键点位,分别对应了五官的一个关键位置,连起来之后形成人的五官。现在点位较多的有240个点的人脸关键点标注,可以包括人的脸部轮廓、唇形、鼻形、眼轮廓、眉轮廓等,形成一张完整的人脸关键点位分布图。
人像识别的关键点标注起来相对比较麻烦,需要把默认的点移动到对应位置上的每一个点,不过正是因为这个标注比较麻烦一点,所以标注一张脸的单价也相对比较高。
另,如需人像识别算法原理此处传送门:http://blog.csdn.net/amds123/article/details/72742578
影像标注单独拿出来是因为这个所在领域是医疗,目前医疗影像识别这一块并不非常成熟,进入门槛比较高,标注员也集中在专职医生上。
刚好,我们自己在做医疗,所以用我们自己的数据来举个例子:
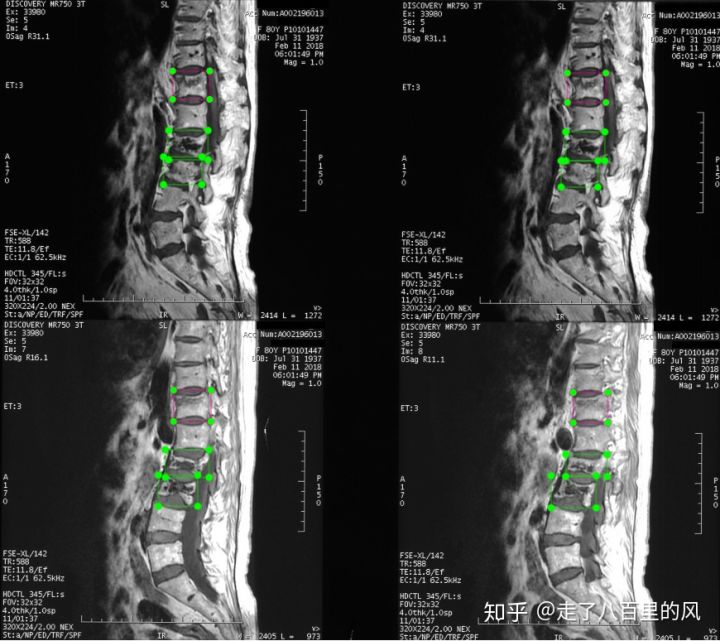
腰椎核磁影像资料
这是一份腰椎的核磁片,从图上我们可以看到T12、L2、L3呈现压缩性骨折征象,T12的程度相对较轻,L2、L3呈现较严重的压缩性骨折征象。故将T12标记为轻度的压缩性骨折,L2\L3为较重的压缩性骨折,用不同颜色的框表示。
这种标注与车辆的拉框标注的方式比较类似,但是因为涉及较为专业的医疗知识,对标注准确性的要求极高,如果做错会造成严重的后果,所以在做的时候通常是选择在职医生、研究生等在闲时来做,对于一些复杂的片子,甚至连这些在三甲医院实习的研究生都做不了,因此标注的资源非常稀缺,标注的成本也相对更高一些,但毕竟是下一个人工智能的风口,竞争其实惨烈,不知道智慧医疗这个行业在经过一段时间的洗牌之后会剩下哪些公司能最终越过龙门。
小声哔哔一句,现在的智慧医疗需要结合在现有的成熟的商业模式之上才能实现落地,空中楼阁般做好一个东西然后想要直接套进医疗行业简直是天方夜谭,现在的智慧医疗大都在起步阶段,尚没有成熟的商业模式承载和足够的落地资金支持。
前段时间有记者跟我聊到标注这个行业,我在这里也说一下我对这个行业的看法吧。
标注这个行业起步其实比较早,我接触过的最早的又从上个世纪就开始专门做数据处理的公司,现在他们处理的已经是来自各国政府、各国大学的数据了,数据处理之专业令我瞠目结舌。但数据标注这一行真正火起来还是在深度神经网络开始在人工智能行业应用的时候。
深度神经网络的学习原理就是用大量的数据去堆砌训练,就像我前面图像拉框的原理介绍那样,数据量越大的时候,机器人的反应也越准确。
所以近两年国内涌现了一大批做数据采集标注的团队和公司。大概分为这样几类:
小团队:大多是5-20一块儿来接一个项目,基本以兼职的形态存在,标注质量难以保证,通常是接一些采集和转手的项目,也有那种从网上招一批兼职的人。当然,这也是收益最低的一部分人。
小公司:大多以5-20个全职+一批兼职的形态存在,标注质量参差不齐,有的标注团队标注质量还是不错的,但有的连试标都看着很难受,这部分人是压价的主力军,大多在四五线地市。

小有规模的数据标注公司:已经有50-100的全职团队,标注质量得到了甲方的认可,收益较为均衡,一般有较为固定的甲方和业务。
众包公司:承接较大型的采集和标注需求,有自己的标注平台和采集工具,质量平台方会做较好的把控。大的众包平台:百度众包、龙猫众包、京东众智等,还有一些新生的标注平台就不一一赘述了。
企业自有平台:像京东、百度、腾讯、阿里这些都有自己的标注平台和标注工具,通过内部人员或者一些外包运营的方式进行数据采集和处理。
总体来说,有规模的公司标注质量会把握的比较好。
此外,国内标注团队的分布也较为集中,小团队主要在河南、河北、湖北的四五线小城,特点是人力成本低,稍大一些的在全国各地都有分布,上海、杭州、成都、贵阳、北京、天津等地较多,特点是资源配比相对较好。
数据标注这个行业的前景,说实话现在我来看现在的很多团队的话,看得不是太好,现在行业的标注绝大多数集中在低端数据标注,诸如普通图像的拉框、声音的转录、文本的简单标注等,这些是人工智能起步的基础数据,呈现的特点是进入门槛很低,一个正常人会使用电脑就可以标注,但是涉及到专业领域的东西就极少有团队能够承接了。
有一个比较现实的问题是:现在的绝大多数团队又只能承接此类标注,特别是四五线城市的小标注团队,我曾放出过一个医疗病历的实体识别类标注,规则稍微有些复杂,但其实只需要背住规则,然后多加练习,认真的话一周左右即可上手,但是我把这个标注任务放给一些小团队的时候我发现,他们在一周以后也没能掌握规则,究其原因,还是因为静不下心去好好学习规则和在联系中反复理解规则,所以虽然这个标注的收益是他们现在标注收益的4倍以上,他们还是做不了。
实际上,现在这些基础的数据标注已经在逐渐被机器所替代,未来需要的一定是有专业的数据标注,比如语音的掺杂外文的标注,图像的医疗影像识别,文本的专业语句标注。
所以最后,还是希望咱们国内的标注团队,逐渐开始积累专业方向上的资源吧,专业方向的众包我还是很看好的。
本文转载自知乎作者王先森,原文链接:http://zhuanlan.zhihu.com/p/36834986。出于传递更多信息之目的,若有来源标注错误或侵犯了您的合法权益,请作者与我们联系,我们将及时更正、删除,谢谢。
