19157628936
lx@jinglianwen.com
时间:2024-06-06 17:09:35

作者:欧陆注册科技

浏览: 次
数据标注的过程——尤其是机器学习项目的大规模有效数据标注活动——呈现出一些复杂性。
鉴于数据是构建机器学习项目的原材料,因此确保其质量至关重要。如果标签缺乏精度和质量,整个基于人工智能的高度复杂的项目可能会因预测模型失效而受到影响。你有没有想过这些数据是在什么条件下产生的?
负责执行数据标注任务的人员了解他们的工作环境至关重要。他们意识到他们的工作对数据集的最终质量的影响也很重要,因此,他们的任务得到认可和重视是很重要的。
众所周知,数据的准备、加载和清理通常需要多达45%的时间用于处理数据。此外,应用复杂的本体、属性和各种类型的标注来训练和部署机器学习模型增加了更多的难度。因此,培训数据标注工作者,确保他们的工作条件和福祉是提高标注工作产生预期质量的机会的关键。
目前,公司拥有大量数据,甚至可以说是过多。最大的挑战是如何处理和标记它们以使它们可用。精确标注的数据有助于机器学习系统建立可靠的模式识别模型,这反过来又构成了每个AI项目的基础。
由于数据标记需要管理大量工作,因此公司通常需要寻找外部团队来处理这个问题。在这些情况下,确保标注者和数据科学家之间的顺畅沟通和协作至关重要,以保持质量控制、验证数据并解决可能出现的任何问题和疑问。
除了语言和地理问题之外,还有其他方面会影响数据的解释,从而影响其正确的标注和标签。标注者在特定领域的经验和他/她的文化联想会留下偏见,只有在过程中意识到这一点,才能控制这种偏见。当主观数据没有单一的“正确”答案时,数据运营团队可以建立明确的指令来指导进行标注的人应该如何解释每个数据点。
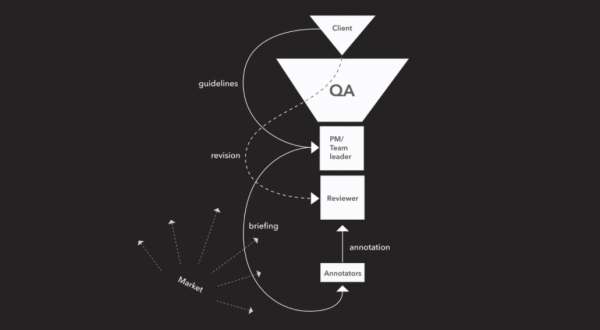
即使数据可能更“客观”,挑战仍然会出现,特别是如果标签分析师不了解他们的工作背景并且没有良好的指示或建立的反馈流程。
在不忽略影响数据标注的各种因素的情况下,在实践中观察到的是训练是这个过程的一个重要方面,因为它有助于“标注者正确理解项目并产生有效(精确)和可靠(一致)的标注”在相关框架内。
