19157628936
lx@jinglianwen.com
时间:2023-01-06 12:20:12

作者:欧陆注册科技

浏览: 次
情感分析的层次级别
现今的情感分析,研究人员主要从文档级、句子级和方面级(aspect level,也有论文称为target)这三个层次粒度对情感分析进行了研究。
现阶段,我认为句子级和方面级的研究多于文档级
情感分析方法包括:基于情感词典的方法、基于机器学习的方法、基于深度学习的方法
1 预处理
由网络爬虫等工具爬取到的原始语料,通常都会带有我们不需要的信息,比如额外的Html标签,所以需要对语料进行预处理。可使用Python作为预处理工具,可用的库有Numpy、Pandas、re、nltk等。
除了可爬取原始预料之外,还存在一些常用开放的语料库。比如Stanford Sentiment Treebank斯坦福情感树库(SSTb),斯坦福推特情绪语料库stanford Twitter Sentiment corpus,Amazon product review dataset亚马逊产品评论数据集等
2 分句、分词等
英文分词
(1)根据空格拆分单词(Split)
(2)排除停止词(Stop Word)
(3)词干提取(stemming)和词形还原(lemmatization)
中文分词
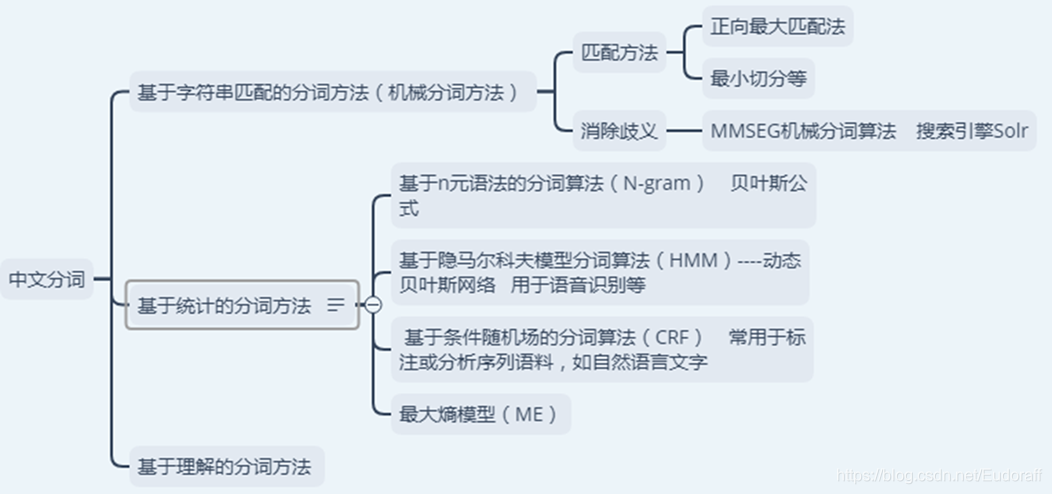

3 情感词与短语的抽取(载入情感词典)
一般来说,词典是文本挖掘最核心的部分,对于文本情感分类也不例外。
4 情感倾向计算
词语级的情感极性分析是句子级和篇章级的情感极性分析的基础和前提,它包括 2 个方面的含义:提取出可能具有情感倾向的候选词;对该候选词进行分析,判断其倾向性及极性强度。
1.预处理
2.分词
3.文本结构化
文本结构化是机器学习中重要的一步,由于文本的特殊性,计算机不能直接理解文本中的语义。需要将文本转结构化以此作为分类器的输入。文本向量化是文本结构化的最重要的一步,其中最主要的是特征提取。
特征提取主要分两种方式:特征选择和特征抽取。
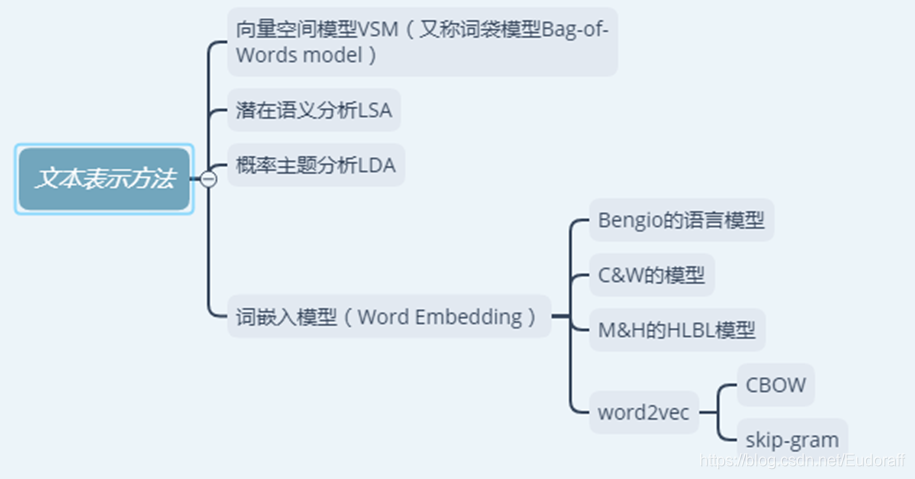
(1)向量空间模型
每一个文本都被映射成多维空间向量中的一个点,以向量的形式给出。对于所有文本,都可以用此模型中的向量(T1,W1;T2,W2;…Ti,Wi;…)来表示,其中Ti为词,Wi为词对应的权重。将文本信息的表示和匹配问题转化为向量空间中向量的表示和匹配问题来处理。
(2)潜在语义分析LSA
潜在语义分析模型使用统计计算方法对大规模的文本进行分析,从而提取出词与词之间的潜在的语义结构。
LSA利用数学中矩阵奇异值分解(SVD)理论来实现降维过程。
(3)主题模型LDA
主题模型基本思想是一个文档被表示为若干隐含主题的随机混合,而每个主题由一组词语的多项式分布组成。LDA模型希望通过将文档表示为一个主题向量来达到特征降维的目的。
(4)词嵌入
词嵌入是一个用低维连续空间来表示词语的过程,方法有word2vec,Glove等。
4.分类算法
常用方法:朴素贝叶斯、最大熵、支持向量机、k近邻模型等。
5.评价
评价指标:
1)准确率Accuracy = (TP + TN)/(TP + FN + FP + TN)
2)查准率Precision = TP/(TP+FP)
3)查全率Recall = TP/(TP+FN)
4)综合评价指标(F-Measure)
F-Measure是查准和查全的加权调和平均:
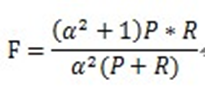
当参数α=1时,就是最常见的F1,也即
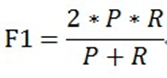
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
1.预处理
2.分词
3.文本表示
4.运用深度学习方法 (这一部分方法太多,编码解码、RNN、LSTM、GRU、CNN、attention等,具体的方法此处就不展开了。)
5.评价
1.社交网络,如基于twitter的情感分析的f1值、准确率都很低
2.跨领域一般就是迁移学习
3.反讽等
4.个人建议 研究句子级的情感分析可以考虑研究跨领域的问题。研究方面级情感分析可以研究方面提取、方面级情感分类或者端到端的方面级情感分析。
————————————————
版权声明:本文为CSDN博主「Eudoraff」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:http://blog.csdn.net/Eudoraff/article/details/100217154/
