19157628936
lx@jinglianwen.com
时间:2022-10-24 11:51:33

作者:欧陆注册科技

浏览: 次
得益于新千年信息技术的快速发展和大数据带来的便利,人工智能依靠大数据迅速地完成了从理论到实际应用,到逐步走进我们的生活,2017年被定义为人工智能应用的元年。那么现在大量人工智能所依赖的数据是怎样进行加工,把海量无序的数据变成机器能够理解的数据的呢?我们今天在这里做一个简单的介绍。
文本标注是对文本进行特征标记的过程,对其打上具体的语义、构成、语境、目的、情感等数据标签,通过标注好的训练数据,我们就可以教会机器如何来识别文本中所隐含的意图或者情感,使机器可以更加人性化的理解语言。

现在数据行业的数据标注对象主要有以下几种类型:文本、声音、图像、视频(多数情况下依然是转换为图像在进行标注);
1、语义识别
语义识别是利用平台对文本进行标注,相同的内容,不同的分割,不同的顺序,表达的意思也会完全不同,所以如果想让计算机能清楚的识别,第一步就要告诉计算机,在每句话中,那几个字是一个词组,这就是分词的过程,而中文有非常强的歧议性,所以准确分词是非常复杂且具有挑战性的。
2、情绪识别
情绪识别原本是指AI通过获取个体的生理或非生理信号对个体的情绪状态进行自动辨别,是情感计算的一个重要组成部分。情绪识别研究的内容包括面部表情、语音、行为、心率和文本等方面,通过以上内容来判断用户的情绪状态。
3、实体识别
一种信息提取技术。从文本数据中获取人名、地名等实体数据。
4、数据清洗
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等,录入后的数据清理一般是由计算机完成。
文本的标注目前我们接触得比较多的行业有:客服、舆情、医疗、教育,应用类型大概有语义识别、情绪识别、实体识别、场景识别、数据清洗、应答识别。
1、在客服领域
客服行业的标注主要集中在场景识别和应答识别这两块,以智能客服机器人为例,用户在与机器交互时,根据用户的咨询内容迅速切入到对应的场景中,然后让用户选择更细分的应答模型,定位到用户实际场景,再根据用户的具体问题,给出对应的回答,整个过程类似于把用户的问题用重新过筛了一遍。
2、在金融领域
由于计算机信息和互联网技术的快速发展,银行服务逐步向网络化、智能化和个性化的方向发展,借助自然语言理解、语音识别技术为主的智能客服机器人,可通过官网、公众号、微博等在线渠道与客户实现智能化人机交互,可有效地减少客服成本并提升服务质量。
3、在医疗领域
利用文本标注,把病症告诉机器人,它会告诉你相关的医学知识,同时提供预约挂号功能及科室导航等服务。医生通过自然语音来“说”病历,智能导诊机器人可以帮助患者解答问题并引导患者就医,智能医学影像识别系统帮助医生对癌症等疾病进行智能读片。
医学专用词汇的优化,可以大幅度提升医生的工作效率。
通过对医院门诊、住院、检验检查、护理等多方面的业务数据进行大数据分析,对医院的行政管理、医疗服务和后勤保障三大类流程进行优化和再造。医院中的导诊服务就是智能客服机器人在医疗领城的典型应用。
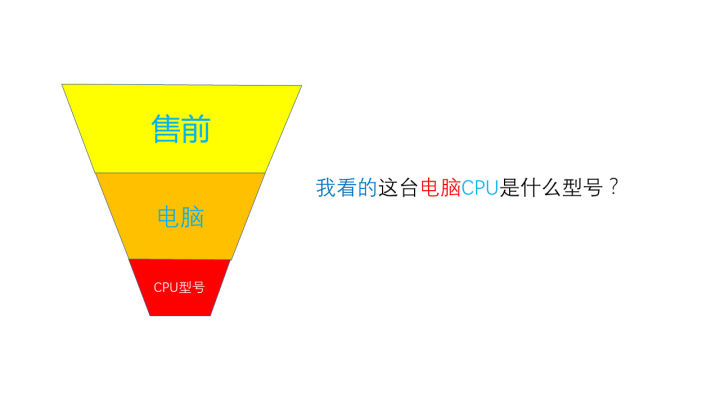
一句话的在机器里的经历
在建立这个应答体系的初期,需要对海量的用户咨询语料进行分类,把对应的用户咨询的问题标记号,放进对应的模型中(其他应答类机器人同理),类似于这样:

语料的分类(实际分类更细,此处仅举例)
这一步的数据标注主要是给句子的场景打标,将用户问题分进对应的场景,这种标注需要非常熟悉本行业业务逻辑树,相当于是在建立机器人的应答知识库,机器人在收到用户发出的指令时识别和哪个细分问题的拟合度最高,然后选取那个问题的答案作为给用户的答案。
标注的方式主要有线上平台标注和线下表格标注两种,根据企业自身情况有所不同,以金融行业某企业的标注的线下表格标注内容举例:

1.客服类分类标注举例
虽然会通过大量整理好的语料尽量穷举对应场景和模型的应答知识库,但是用户提问的方式不一样,上下文内容和场景不一样,同时机器的识别是一个概率问题,最终识别成什么问题,以及最终给出什么答案都存在一个阈值,所以这个识别是可能会出现错误的。
出现错误的情况我们称为badcase,这个阶段的标注就是标注员去对原始的聊天数据进行标记,看机器人的回答是否正确,如果不正确,那么出现的问题是哪一种,是一级分类错误还是二级分类错误还是回答的答案不够好,不能够满足用户的问题需求。例如:用户问银行卡怎么办理,机器人回复的是信用卡的办理流程,那么这时候就是一个badcase,机器人把问题放进了错误的分类导致回答了一个错误的答案。
这一步的标注是将出现的错误筛选出来,并根据业务逻辑树进行问题的分类,标记完之后由专门负责处理badcase的同事和研发的同事一起对应答情况进行调优。【这一步是一个长期的过程,需要一个稳定且熟悉这个业务的团队进行标注】
再举一个自然语言识别的例子,普通的自然语言识别,从里面提取时间地点人物这些信息的就不举了,目前市场上已经太多这样的标注团队了,标注的内容比较基础,我这里拿一个我处理的一个医疗行业的自然语言处理标注。
这是一个专业度要求比较高的标注,我们还特意招聘了医生和教语言的老师来进行标注,标注的对象是从病历中抽取出来的一些字段,病历里面的体查项和既往史这些是有模板的,可以较小的工作量就能穷举,直接识别可替换项的结果就行了,但是主诉和医生对患者的描述每次会有所不同。
于是我们的标注就是第一,标注每个词的属性,即每个词在这种语境下面是怎样的属性(相同的词在不通的情况下会有不同的属性),第二,标注每个词在句子中的作用。
还是举个例子:这是一句主诉:腰痛两年,伴左下肢放射痛10日余。
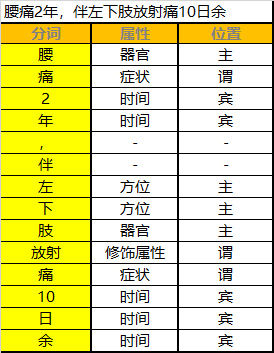
2.医疗标注举例
这样标注的目的在于让机器去识别病历中的每一个词,通过大量的数据标注之后机器能够认识到一个词有哪些属性,在句子中扮演什么角色,在这个语境情况下这个词扮演什么角色,并且教会机器去拆词,识别哪些词是有用的,哪些词是无用的。
同理,日常对话类的自然语言识别用途的标注原理大都类似,但规则有所不同。
推荐阅读:
本文转载自知乎作者王先森,原文链接:http://zhuanlan.zhihu.com/p/34959177。出于传递更多信息之目的,若有来源标注错误或侵犯了您的合法权益,请作者与我们联系,我们将及时更正、删除,谢谢。
