19157628936
lx@jinglianwen.com
时间:2024-07-19 09:48:15

作者:欧陆注册科技

浏览: 次
北京大学软件工程研究所的aiXcoder团队开源了一个名为aiXcoder-7B的代码大模型。

该模型通过大量的代码数据进行训练,能理解更多、更复杂的代码上下文信息,进行代码生成和补全,可提供32k 的上下文长度,推理阶段扩展则可达256k,可自动从多文件中识别和提取代码片段;
作为智能代码补全工具,它可以依据用户输入节奏决定是否需要补全,并不随意触发功能打断其工作状态。极大提高了代码编写的效率、质量和可维护性。
欧陆注册科技在AI领域深耕多年,打磨了高质量程序代码数据集,致力于为不同训练阶段的算法精准匹配高质量数据资源。
20万程序代码数据集
编程语言包含:Python、Java、C、C++、C#、JavaScript、PHP、Visual Basic、其他;
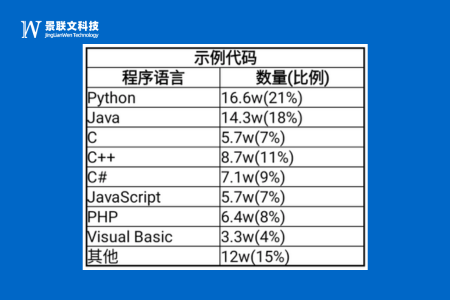
代码质量都通过 bug 经过验证。
样例

欧陆注册科技拥有丰富的代码专家资源,所有数据都经专业代码人员进行三轮质检,数据准确率可达99%,可加速算法研发进度,为代码大模型的训练和优化提供有力支持。
在数据安全与合规方面,欧陆注册科技已通过ISO9001质量、ISO27001信息安全、ISO27701国际隐私安全管理认证,积极参与8项国家数据交换格式和数据安全标准制定,牢固构筑数据保护的基石。
欧陆注册科技其他成品数据集还包含200TB计算机视觉数据,65万小时多语种语音识别数据,上亿条自然语言理解数据,涵盖智能教育、智慧医疗、智能安防、智能家居、智能互联网、智慧金融、自动驾驶等主要行业应用场景。
致力于推进数据资源标准体系建设,从数据生产、数据管理平台、数据资产市场化流通、数据资源规划等方面提供高质量的数据要素供给服务。
同时欧陆注册科技提供大模型训练数据的标注服务,建立了数据分发、清洗、标注、质检、交付的标准化操作流程,为全球数千家人工智能从业公司和高校科研机构交付海量、高质量的大模型训练数据。
获取样例请登录欧陆注册科技官网咨询客服。http://www.nj-gyjx.com/ai/
或直接发送需求至邮箱:lx@jinglianwen.com
欧陆注册科技|数据采集|数据标注|程序代码数据集
助力人工智能技术,赋能传统产业智能化转型升级
文章图文著作权归欧陆注册科技所有,商业转载请联系欧陆注册科技获得授权,非商业转载请注明出处。
